JPA Repository 의존성을 끊어보면서 (Fake Object 를 만들어 보자)
문서 업데이트: 2024-08-30
느낀 점
부터 말씀드리자면, 왜 의존을 끊으려고 하고 있을까 하는 의문이 들었습니다. JPA Repository와의 의존을 끊는 일에 적지 않은 수고가 따랐습니다. 이전이었다면 Mockito 의 @Mock, when().thenReturn() 을 통해 stub으로 끝났을 일을 크게 만들고 있는 것이 아닌가 싶었습니다.
한편으로는 현재 궁금한 점은 ‘실제 프로덕션 환경에서 값이 잘 들어가고 나오는가?’가 대부분입니다. 프로덕션 환경에서의 결과를 알기 위해서는 @SpringBootTest, @DataJpaTest 가 제공하는 컨텍스트가 필요합니다.
돌고 돌아보니, 서비스 레이어에서 크게 의심할 부분이 없는 것(없다시피 하는 도메인)이 이런 의문을 품게 하는 요인이라 생각합니다. (리포지터리 조회 시 Optional.empty() 인 경우 예외를 던지는 것 외에는 역할이 따로 없다 보니..) 좀 더 도메인이랄 것을 추가하는 것이 필요하겠습니다.
느끼는 바가 위와 같았기에 ‘굳이 현재 수준에서 FakeRepository 를 만들어야할까?’와 같은 생각이 듭니다.
다만 FakeRepository를 구현하면서, 데이터베이스와 프레임워크가 대신 해주는 일을 적은 부분이나마 모방해 직접 Java 코드로 구현해 보는 경험을 해본 것은 흥미로웠습니다.
배경
이전 포스트에서 테스트 대역에 대해 알아보던 중 아주 잠깐 테스트 대역을 만들어보고자 했습니다. 의존성 역전을 통해 구현체를 의도에 따라 갈아 끼울 수 있다는 점을 직접 사용해보고 싶었습니다.
서비스 레이어가 JpaRepository 에 직접 의존하는 경우,
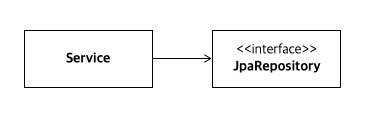
해당 repository 객체를 대신하는 대역을 만들기 위해서는 ...Repository extends JpaRepository<T, ID>가 상속하는 모든 메서드를 구현해야됨을 알 수 있었습니다.
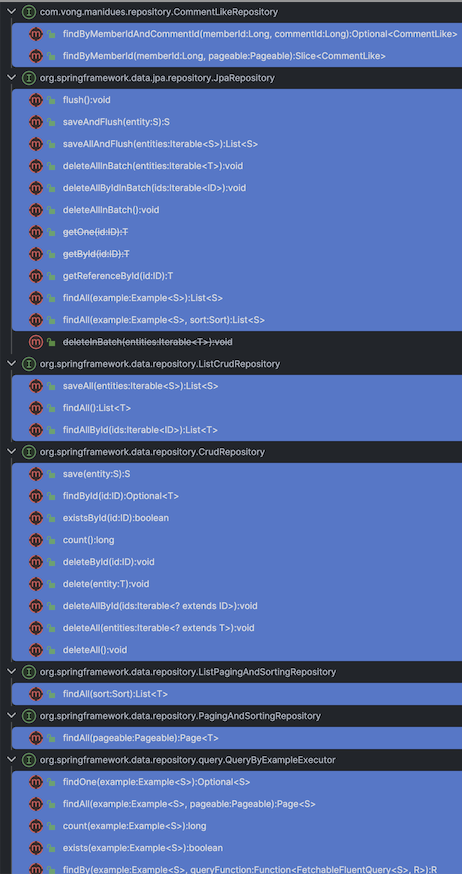
문제
직접 사용하지 않는 메서드는 dummy와 같은 응답을 하게 두고 사용하는 메서드만 구현해 Fake 응답을 할 수도 있겠지만, 사용하지 않는 메서드 모두 코드에 존재해야 하는 것이 문제라고 생각했습니다.
또한 의존성 역전을 통해 적절한 수준에서 의존을 끊어내는 방식을 배웠으니 적용해 보고자 했습니다.
우선 기존 프로젝트에서 브랜치를 하나 나누고 작업에 임합니다.
적용
Service가 JpaRepository에 직접 의존하지 않고, 인터페이스 ServiceRepository를 통해 JpaRepository 를 호출하는 방식입니다.
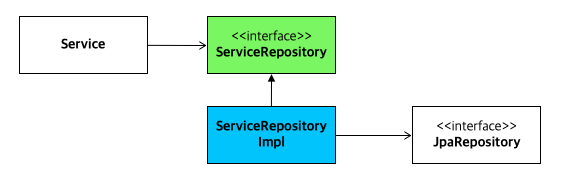
이 구조와 같이 되면 ServiceRepository 는 다음의 예시처럼 됩니다.
public interface MemberRepository {
Optional<Member> findByEmail(String email);
Optional<Member> findByNickname(String nickname);
Optional<Member> findById(Long id);
Member save(Member member);
Member update(Member member);
}
그리고 이 인터페이스를 구현한 ServiceRepositoryImpl은 다음과 같습니다.
다음의 객체가 JpaRepository에 의존하고, 호출을 담당하게 됩니다.
이후는 Service가 JpaRepository에 직접 의존하는 상황과 같이 JpaRepository의 메서드 호출과 응답이 이뤄집니다.
public class MemberRepositoryImpl implements MemberRepository {
// 이 곳에서 JpaRepository 에 의존.
private final MemberJpaRepository memberJpaRepository;
@Override
public Optional<Member> findByEmail(String email) {
return memberJpaRepository.findByEmail(email);
}
@Override
public Optional<Member> findByNickname(String nickname) {
return memberJpaRepository.findByNickname(nickname);
}
@Override
public Optional<Member> findById(Long id) {
return memberJpaRepository.findById(id);
}
@Override
public Member save(Member member) {
return memberJpaRepository.save(member);
}
@Override
public Member update(Member member) {
return memberJpaRepository.save(member);
}
}
이후 테스트 대역으로 사용할 객체를 만들어 줍니다.
서비스가 repository 객체의 메서드를 호출할 때, 전달하는 인자에 따라 실제와 비슷하게 동작하는 repository 객체를 만들고 싶어 FakeRepository를 만들어봤습니다.
class FakeMemberRepository implements MemberRepository {
}
이렇게 되면 FakeRepository 는 그림처럼 위치하게 됩니다.
FakeRepository의 책임은 실제 JpaRepository의 기능을 모방하고, 데이터베이스와 통신하듯 행동하는 것입니다.
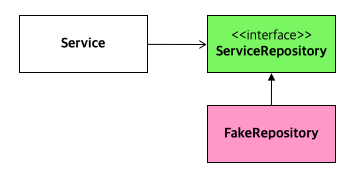
또한 구현해야 할 메서드는 다음과 같이 줄어듭니다.
좋았습니다. 이제 서비스 레이어를 테스트할 때, 테스트 대역 프레임워크인 Mockito를 통해 동작 중 만나는 의존 객체의 stub을 일일이 작성하지 않고, 테스트 속도가 늘어나는 데 일조하는 DataJpa 컨텍스트를 불러오지 않아도 됩니다. 동적으로 동작하는 FakeRepository를 통해 테스트할 수 있습니다.
중간 정리
- 테스트 시, 메서드 호출에 사용하는 인자를 통해 동적으로 응답하는
FakeRepository생성.Mockito로 때에 따라 다른stub을 작성하지 않음.DataJpa컨텍스트를 부르지 않고JpaRepository동작과 유사하게 작동하는 더 빠른 객체FakeRepository를 사용.
하지만 이것이 저에게 가져다주는 의미가 뭐가 있는지 생각해 봤습니다.
stub을 생성하지 않지만FakeRepository에는JpaRepository가 마법처럼 수행해 주던 로직을 모방해 코드를 짜야 합니다.- 빠른 테스트는 속이 시원해서 좋습니다. 하지만 현재 수준에서는 실제 데이터베이스에 올바르게 데이터가 잘 저장되고 잘 돌아오는지 실제 동작이 궁금한 경우가 더 많습니다.
다시 말해 서비스에서 테스트할 것이 잘 없습니다. 소위 빈약한 도메인을 가지고 있는 CRUD 게시판 서비스에서는 과연 이것이 필요한가 싶습니다.
어쩌면, JpaRepository와의 결합을 끊으면서 느낀 점은 여기서 끝이 났을 수도 있습니다.
다시 돌아와서 (FakeRepository 구현)
어쨌거나 저쨌거나 시작했으니 소기의 목적을 달성하기 위해 저의 FakeRepository가 실제 데이터베이스와 통신하듯 구현을 해봅니다.
우선 해당 repository의 대상인 Member 테이블 행세를 할 List<Member>를 만들고, Id(autoIncrement) 또한 만들어줍니다.
여러 테스트를 한 번에 돌릴 때도 id 문제없이 잘 수행돼야 하므로, 해당 객체가 생성될 때마다 필드를 초기화합니다.
class FakeMemberRepository implements MemberRepository {
@Getter
int autoIncrement = 0;
private final List<Member> memberMap = new ArrayList<>();
}
save()는 다음과 같습니다.
Member객체의 주요 필드는Not null제약 조건을 가집니다.Member.emailMember.nickname은Unique Key로 설정되어 있기에, 리스트에 존재한다면 예외를 던져줍니다.- 저장이 되면
autoIncrement는 다음에 저장될 객체의Id로 후치++ 증가합니다.
(예외 발생 시 원래의 값으로 감소)
@Override
public Member save(Member member) {
Objects.requireNonNull(member.getEmail());
Objects.requireNonNull(member.getPassword());
Objects.requireNonNull(member.getRole());
Objects.requireNonNull(member.getNickname());
Member memberWithId = Member.builder()
.id((long) autoIncrement++)
.email(member.getEmail())
.password(member.getPassword())
.nickname(member.getNickname())
.role(member.getRole())
.registerDate(LocalDateTime.now())
.build();
boolean isDuplicatedEmail = memberMap.stream().findAny()
.filter(each -> each.getEmail().equals(member.getEmail()))
.isPresent();
boolean isDuplicatedNickname = memberMap.stream().findAny()
.filter(each -> each.getNickname().equals(member.getNickname()))
.isPresent();
if (isDuplicatedEmail) {
autoIncrement--;
throw new DataIntegrityViolationException("duplicated email");
}
if (isDuplicatedNickname) {
autoIncrement--;
throw new DataIntegrityViolationException("duplicated nickname");
}
memberMap.add(memberWithId);
return memberWithId;
}
findBy...() 을 구현하면서, Id가 테이블의 Primary key로 절대적인 식별자이니,
- ‘내부적으로는
Id를 통해 조회하게끔 로직을 짜게 됐네?’ - ‘이런 게 데이터베이스에서 말하는 인덱스 개념인가?’
와 같은 어렴풋한 생각이 들었습니다.
@Override
public Optional<Member> findById(Long id) {
try {
return Optional.of(memberMap.get(id.intValue()));
} catch (NullPointerException e) {
return Optional.empty();
}
}
@Override
public Optional<Member> findByEmail(String email) {
Member member = memberMap.stream()
.findAny()
.filter(each -> each.getEmail().equals(email))
.orElse(null);
Objects.requireNonNull(member);
return findById(member.getId());
}
@Override
public Optional<Member> findByNickname(String nickname) {
Member member = memberMap.stream()
.findAny()
.filter(each -> each.getNickname().equals(nickname))
.orElse(null);
Objects.requireNonNull(member);
return findById(member.getId());
}
추가로, 테스트하다 보니 분리의 필요성을 느낀 update() 메서드.
JpaRepository 로직을 흉내 내다 보니, 엔티티의 필드 중 일부를 수정하는 경우, hibernate 이 제공하는 1차 캐시, 엔티티의 동일성 여부를 구현해야 할 필요가 생겼는데, 이것까지 실제 구현하기는 어려움이 있다고 판단했습니다. 그 때문에 실제 동작은 JpaRepository.save() 이지만 둘의 구분이 필요했고, 프로덕션 코드의 변경에 영향을 주게 됐습니다.
@Override
public Member update(Member member) {
memberMap.add(member.getId().intValue(), member);
return member;
}
돌아보며 느낀 점
여기까지 읽어주셨다면 ‘현재 앱의 수준에서 이와 같은 구성은 과하다’라고 느끼는 작성자를 보셨을 텐데요. 구현하고 돌아보며 느낀 바는, 서비스 수준에서 테스트할 만한 복잡한 로직이 필요해진다면, 잘 짜둔 FakeRepository를 통해 재사용하면, 지금은 예상하기 힘든 부수 효과를 누릴 수 있을 것 같다는 생각이 듭니다. abstract, Generic으로 일부 공통 메서드를 추상화하면, 재사용성에서도 좋지 않을까? 하는 생각이 듭니다. 결과적으로는 식견을 넓히는 경험이고, 앞으로 발전시켜 보고 싶은 욕심이 많이 드는 과정이었습니다.
테스트가 필요한 부분을 잘 선별해 내는 것 또한 필요한 역량인 것 같습니다.
감사합니다.